
こんにちは!クララ株式会社のAWS Secure開発プロジェクトチームです。
前回の記事では、Security Hubスコアの仕組みやSuppress(抑制)の考え方についてお話ししました。
👉 前回の記事はこちら:

今回はその続編として、
- スコアを改善するには、何から始めればいいのか?
- 現場で実践できる運用体制の整え方は?
- 継続的に改善できる仕組みとは?
このあたりを実践例とともに、わかりやすく整理して解説していきます。
スコアを改善するには「対応より設計」から
Security Hubのスコアを上げたいと思ったとき、まず目につくFailを消したくなるのは自然な流れです。
でも、いきなり手を動かす前に大事なのが、運用をどう“回す”かという設計です。
スコア改善の3ステップ
- 通知のチューニング(うるさすぎず、見逃さない設計)
- 対応方針の明確化(誰が・何を・いつまでに)
- 改善のルール化(サイクルとして回る仕組み)
ただアラートを見るだけでは、改善は定着しません。
“仕組みで動く”運用体制こそが、継続的なスコア改善のカギです。
通知は「静かなアラート」にするのが鉄則
通知が多すぎると、本当に危ないものが埋もれてしまうことも。
通知設計を間違えると、次のような“あるある”に陥ります:
- Lowレベルのアラートが多すぎて、大事なものが見えない
- 通知が多すぎて、誰も見なくなる
- 対応が属人的になり、放置されがちに
おすすめ通知・対応設計例
| レベル | 通知対象 | 通知手段 | 対応期限 |
| Critical | 全件通知 | Slack / メール | 即日〜24h以内 |
| High | 要約通知 | メール+週次レポート | 72h以内 |
| Medium | 月次集計 | ダッシュボード | 1ヶ月以内 |
| Low | 通知なし | CloudWatch Logsなど | 状況次第 |
通知は「全部知らせる」ではなく、「必要な情報だけを確実に届ける」ことが大原則です。
Security Hubスコアを改善するための構成修正アクション
Failを見つけたら、まずやるべきは**「なぜそれがFailになっているのか?」**という構成レベルでの確認です。
対応の優先順位
- Critical:即時対応
例:S3バケットが公開/重大な脆弱性が未修正 - High:1週間以内に計画的対応
例:0.0.0.0/0が許可されているSG - Medium/Low:月次棚卸し or Suppress検討
例:暗号化されていないリソースなど
よくあるFailとその意味・重要度・対応アクション
- S3.2:S3バケットがパブリックアクセス許可(CRITICAL)
→ バケットポリシーやACLを見直し、BlockPublicAccess を有効化。Terraformなどで管理するのが望ましい。 - EC2.7:EBSボリュームのデフォルト暗号化が無効(HIGH)
→ EC2のEBS設定で「デフォルト暗号化を有効」にする。IaCで暗号化指定を明示。 - RDS.1:RDSスナップショットがパブリックにアクセス可能(CRITICAL)
→ スナップショットの公開設定を制限し、ポリシーやスクリプトに明示的に含める。 - IAM.6:ルートユーザーの使用が検出された(HIGH)
→ ルートユーザーはMFA有効かつ緊急用に限定し、通常運用はIAMユーザー/ロールに切り替える。 - CloudTrail.3:ログファイル整合性が無効(MEDIUM)
→ CloudTrailで「ログファイル検証」を有効化、整合性監視をCloudWatch Logs経由で運用。 - EC2.4:セキュリティグループが0.0.0.0/0を許可(CRITICAL)
→ 必要なIPレンジに絞り、CIDR制限。Terraformでセキュリティグループテンプレート管理。 - Lambda.1:関数に対するIAMロールの権限が過剰(HIGH)
→ 最小権限のIAMポリシー設計(AWS管理ポリシーを使わずカスタムで制限)。 - S3.5:バケットにログ記録が無効(MEDIUM)
→ S3アクセスログやCloudTrailログを有効化し、ログバケットを分離して運用。
修正後の定着アクション
- 修正方針をテンプレート化(例:CloudFormation, Terraform)
- 修正内容をCI/CDに組み込み、再発防止と再現性を確保
- 改善済みかをSecurity Hubで再チェック → Passに変わったか確認
属人化を防ぐ──“担当者任せ”にしない仕組み作り
Security Hubの運用が続かない最大の理由のひとつが、属人化です。
- 通知設定を担当者しか理解していない
- 対応状況が個人のメモに残っていて他の人が追えない
- スコア改善の方針がチームで共有されていない
おすすめの属人性排除策
- 通知設定やフィルター条件を設定
- 運用フローをドキュメント化して、誰でも引き継げる状態に
- 月次の振り返り+可視化ダッシュボードで改善状況を共有
属人化を解消することは、運用の継続性と品質に直結します。
ベストプラクティス:Security Hubを“動かす”ための4原則
Security Hubを単なる“確認ツール”で終わらせず、継続的な改善を支える仕組みに変えるには、いくつかのポイントを押さえた運用が必要です。以下は、よくある課題とそれに対するベストプラクティスの対処法を整理したものです。
| 課題 | ベストプラクティス |
| 通知が多すぎて埋もれる | レベルごとに通知チャンネル・頻度を分ける |
| Fail対応が属人化している | 手順を標準化し、月次で棚卸し |
| Suppressが場当たり的 | ルール化+期限設定+理由を記録 |
| 改善が定着しない | レポートと振り返りを習慣化 |
これらは、単体では小さな工夫に見えるかもしれませんが、「セキュリティ運用がチームで回る」ようにするためには不可欠な要素です。Security Hubが出すスコアやアラートを「読む・判断する・動く」ための下支えとして、仕組み化は最重要とも言えます。
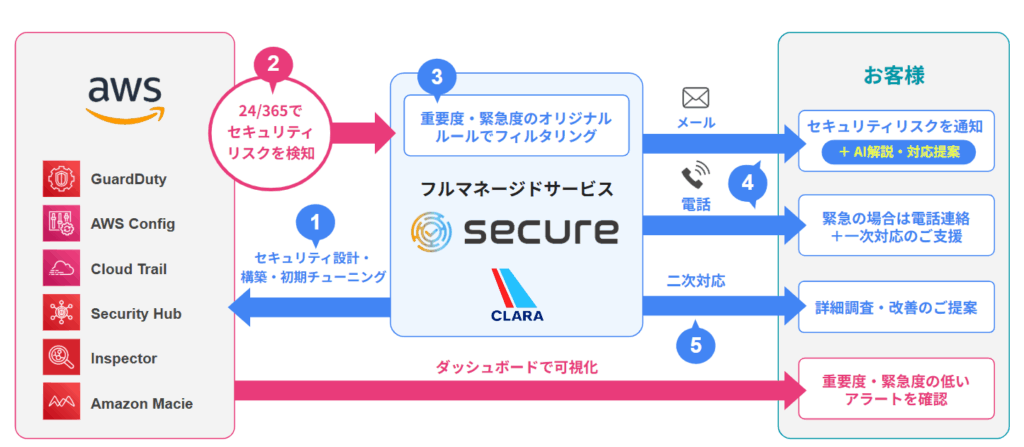
AWS Secureが支援する、“回るセキュリティ運用”の実現
クララ株式会社の AWS Secure は、Security Hubを最大限活用するための運用全体を支援するサービスです。
- アラートの内容を整理・最適化し、重要度別に通知
- 月次でアラート傾向を集計、チームで振り返る
- 通知の設定・運用フローの標準化支援
- Slackやメールとの通知連携、構成改善支援
- 属人化を防ぐための仕組み・ルール化支援
Security Hubを“見るだけ”のツールから、“動ける仕組み”に変える──
その中心にあるのが、AWS Secureの支援価値です。
📄 詳細はこちら

まとめ:スコアの“上げ方”は、仕組みで決まる
Security Hubスコアの改善は、「見て対応する」だけではなく「仕組みで支える」ことが鍵です。
- 通知の精度を上げ、重要な情報だけを拾う
- 属人性を排除し、組織としての判断と運用に昇華させる
- Failを見逃さず、構成修正に結びつける
- 改善サイクルを回し続けることで、スコアは自然と上がっていく
AWS Secure開発プロジェクトチームは、こうした“回る運用”を実現する支援をしています。
Security Hubの導入後に運用がうまくいかないと感じている方は、ぜひご相談ください。







